This webinar covers common database outages and how to avoid them using Oracle Database on AWS, Azure, or GCP. FlashGrid CEO Art Danielov presented it at Ascend 2024.
The advice shared draws on the practical experience of using FlashGrid software to enable high-availability architectures for mission-critical databases in the cloud since 2017.
Oracle Database powers thousands of mission-critical applications and services, which may be affected if their databases experience downtime (scheduled or unplanned).
To avoid this, we can implement a HA (highly available) architecture for maximum database uptime. However, its design is critical: it must have reliable components, systems sized adequately for workloads, properly configured software, workload limits, maintenance plans, and continuous testing, analysis, and improvement.
Multi-AZ may benefit an HA architecture. It protects against failures affecting an entire data center, such as a cooling outage. If the issue is resolved quickly (e.g., within less than a day), expensive or complex DR procedures can be avoided. Synchronous data replication can be performed because there is low latency between availability zones, which enables Zero PRO.
Using multi-AZ has some considerations. The latency between AZs is higher than within a single AZ, but this is rarely an issue; the exact values are listed in this article. We must carefully plan how resources are placed, including databases and the application tier.
Depending on budget and requirements, you may opt to use multi-AZ, multi-region, or both together. There is some overlap, but each has different benefits and use cases.
|
Multi-AZ |
Multi-Region |
| Active-Pasive HA |
Yes |
No |
| Active-Active HA |
Yes |
No |
| Local Disaster Recovery |
Yes |
Yes |
| Major Disaster Recovery |
No |
Yes |
Recovery From
Regional Cloud Service Outage |
No |
Yes |
| Latency |
<1 ms |
10-100ms |
| Data replication |
Synchronous |
Asynchronous |
| RPO |
Zero |
Non-Zero |
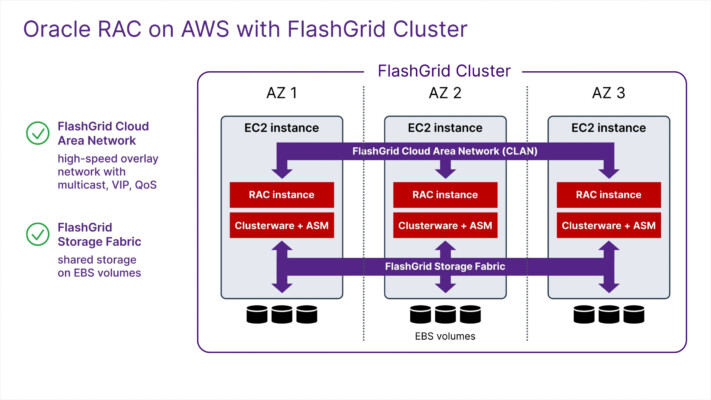
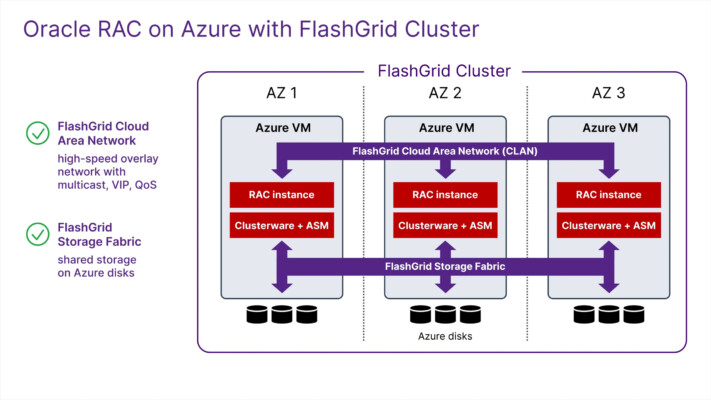
There are several Multi-AZ options available for Oracle Database on AWS, Azure, and Google Cloud. Some, like Amazon RDS for Oracle, are engineered, supported, and managed by the cloud vendor. Conversely, you can build your own Oracle DB server setup using Data Guard FSFO, where you design, manage, and support it. There are several options in between, engineered and supported by FlashGrid, where the customer retains control. Which is best for a specific use case will depend on technical compatibility, target uptime, and the internal expertise available.
|
Engineered
and
supported
by |
Managed
by |
Target
Uptime
SLA |
Anticipated
Downtime
Per Year |
| Amazon RDS for Oracle |
Cloud
vendor |
Cloud
vendor |
99.95% |
<4 hours |
| Build-Your-Own Oracle DB Servers + DG FSFO |
Self |
Self |
99.95% (?) |
<4 hours (?) |
| FlashGrid Server + DG FSFO |
Vendor
+ Self |
Self |
99.95% |
<4 hours |
| FlashGrid Server for Oracle Failover HA |
Vendor |
Self |
99.95% |
<4 hours |
| FlashGrid Server for Oracle RAC: 2 nodes |
Vendor |
Self |
99.99% |
<1 hour |
| FlashGrid Server for Oracle RAC: 3+ nodes |
Vendor |
Self |
>99.99% |
< 0.1 – 1.0
hour |
When designing an Oracle Database server for an HA setup, you must be aware of failure modes. The failures that are usually anticipated include cloud instance failure, a dead disk, or a database crash. In our experience, other failure modes are more challenging to deal with: out-of-memory and swapping, connection storms, disk i/o freezing, network disruptions, and various other failure modes due to configuration errors. Ensuring that these are avoided requires a lot of testing and iterations.
When an error occurs, we want to isolate it as quickly as possible. Clear errors/failures are easy to handle, ie. Disk i/o returns an error, the network becomes fully unavailable, or the system is rebooted. However, if these errors repeat or are intermittent, they can create double failures and require timely isolation. Brown-outs are the most dangerous, where the system is neither alive nor dead, such as swapping due to low memory, connection storms, and running low on critical system resources. At FlashGrid, we take strict measures to prevent these.
Disk I/O is critical for database functioning, and failures happen. This raises questions about what happens in different scenarios. The only way to find out is to conduct tests, then further tests for various disk types, and more tests after changing the cloud instance type or upgrading the OS. In AWS, you can use the AWS Fault Injection Simulator for EBS to generate errors and freeze items to see what will happen, e.g., will your HA handle the scenario?
To summarize, building your own HA setup requires a significant and continuous investment of engineering resources, highly skilled database and cloud engineers 24/7, and correct configuration. Otherwise, it may result in extended downtime.
A pre-integrated HA solution will have a shorter deployment schedule, reduced risk of configuration errors (due to extensive testing and experience with other customers), and 24×7 support. Technical support is important as errors will still happen. Engineers can also help with preventing errors and optimization.
Maintenance and patching often require downtime. Although this can sometimes be scheduled, it raises issues about the impact on the application or service. With active-active HA/RAC, zero downtime during maintenance is possible, making it much easier to plan and perform.
Combining RAC and Multi-AZ enables 99.999% uptime for Oracle Database. RAC provides near-zero RTO. With active-active HA and Multi-AZ, it can survive a double failure with 3+ RAC nodes and an outage affecting the entire data center. It avoids the need for DR failover during data center outages (e.g., up to 1 day). Services like FlashGrid’s Active Reliability Framework can provide node-level reliability and failure isolation.
To achieve your required uptime SLA, you must set a higher database uptime SLA. Then, choose a database HA architecture that enables the required uptime SLA and the DR and backup strategies. Decide between build-your-own vs. pre-integrated HA and how you will continuously monitor, adjust, and support during the system’s lifetime. To avoid downtime and balance costs, ensure that the database and the app tier are sized and used correctly.
We’ve reviewed the available database HA options in the cloud and how to use them to avoid database outages. We hope you found the information useful. If you have any questions, don’t hesitate to contact us.




 Download slides
Download slides