When architecting your application’s infrastructure in the cloud for better uptime and business continuity, you will likely face the question of using multiple availability zones (AZ) vs. multiple cloud regions vs. both multiple regions and multiple AZs per region. In this post, we will discuss how these options compare and how to use them to achieve your objectives. The information is backed by 7 years of our experience at FlashGrid enabling mission-critical Oracle databases on AWS and Azure clouds for organizations of various types and sizes.
Fast forward to the summary: Use multi-AZ for high availability and uptime SLA of 99.99% or higher. Multi-AZ can also protect you against data center outages or “local disasters”, which happen more often than major disasters. Use multiple regions for protection against a regional cloud service outage or a major disaster. The table below sums it up.
| Multi-AZ | Multi-Region | |
|---|---|---|
| Active-Active HA | Yes | No |
| Active-Passive HA | Yes | No |
| Protection against Data Center Outage | Yes | Yes |
| Protection against Regional Cloud Service Outage | No | Yes |
| Protection against a Local Disaster | Yes | Yes |
| Recovery from a Major Disaster | No | Yes |
| Latency | <1 ms | 10-100 ms |
| Data Replication | Synchronous | Asynchronous |
| RPO | Zero | Non-Zero |
To learn more, read on.
Regions and Availability Zones
AWS, Azure, and Google clouds have multiple independent regions. The fact that the regions are operated independently provides protection against most cloud outage types. Typically, there are long distances between regions, which makes the use of multiple regions suitable for protection against even major disasters. However, this comes at the cost of high latencies, which makes the use of synchronous data replication between regions impractical.
Each region is partitioned into three or more availability zones (except for a few Azure regions that do not yet have AZs). Each availability zone consists of one or more discrete data centers housed in separate facilities, each with redundant power, networking, and connectivity. Each availability zone is physically separate, so local disasters like fires or flooding would affect one AZ only.
Although availability zones within a region are geographically isolated from each other, they have direct low-latency network connectivity between them, making them the more practical choice for synchronous data replication.
High Availability and Fault Tolerance
A highly available architecture ensures that the application service continues running with minimal or no downtime when any of its parts is taken offline for maintenance or fails unexpectedly. Keeping the services up through planned maintenance events is achievable through redundancy or failover of resources located in the same data center or availability zone. However, spreading the resources across availability zones is highly desirable for better fault tolerance.
With “traditional” self-built and self-managed data centers, implementing and maintaining an Active-Active or even Active-Passive HA architecture spanning multiple data centers could be prohibitively complex and expensive. But today, by leveraging cloud availability zones and Infrastructure-as-Code (IaC), it is easy to implement such HA architectures using out-of-the-box blueprints and templates.
The uptime SLAs are getting stricter with more critical services now delivered directly to consumers through online and mobile apps. If one hour of unplanned downtime is unacceptable for your service then you probably need uptime SLA of 99.99% or higher, which requires the use of multiple availability zones. AWS, Azure and GCP all have uptime SLAs of 99.9% for a single VM and 99.99% for a pair of VMs spread across two AZs.
An uptime SLA of 99.999%, which is only 5 minutes of downtime per year, is achievable by combining the multi-AZ approach, double redundancy, active-active HA, and strict maintenance and change management processes. The most challenging may be configuring the active-active HA in the database tier. In the case of Oracle Database, Oracle RAC clustering technology can be used for active-active database HA across availability zones.
Data Center Outages
A data center outage is characterized by a significant percentage of resources located in the same data center failing simultaneously. Possible reasons for such outages range from software configuration errors from cloud providers to backbone switch failures and weather events causing temporary power and cooling outages.
At FlashGrid, we’ve seen that the most frequent cause has been storage service outages lasting several hours. FlashGrid customers with multi-AZ clustering got through the outages with minimal or zero disruption. After the outage, some unlucky customers with single-AZ architecture in the affected data centers decided to switch to multi-AZ.

Other notable examples of cloud data center outages:
- Cooling failures affected data centers of Google Cloud for 14 hours and Oracle Cloud for 22 hours in the UK on July 19, 2022, due to extremely hot weather. Only one availability zone was affected in Google Cloud: the scope of impact in Oracle Cloud is less clear.
- A lightning storm in Sydney on August 30, 2023, affected the power supply of the cooling system in the data center shared by Azure Cloud and Oracle Cloud. In Azure Cloud, only one of the three availability zones was affected. Unfortunately, Oracle Cloud customers had only this availability zone (or “availability domain” in Oracle Cloud’s terminology) in that region.
There are alternative mechanisms for reducing the chances of being affected by a data center outage, such as spread placement groups in AWS or availability sets in Azure. However, they are limited in their ability to protect against some failures and thus are not a proper substitute for a multi-AZ architecture.
Regional Cloud Service Outages
Some of the cloud services, such as Amazon S3, are “regional” (vs. “zonal”), which means the distribution of the service resources across availability zones is managed by the cloud provider, and not by the customer. A regional cloud service typically has sufficient redundancy and fault tolerance to protect it against most failures. However, outages of a regional cloud service may still happen and have happened in the past; most are caused by software or configuration errors.
Any critical dependencies of a “zonal” resource (e.g. a database or an application instance located in a particular AZ) on regional services should be eliminated or minimized.
If your application stack has a critical dependency on a regional service, it may be a good idea to plan for a failover to a different region. Having the entire application stack in a “warm” state in a different region is very helpful for reducing the RTO (Recovery Time Objective).
A crucial difference between this scenario and a major disaster affecting the entire region is that a service outage will likely be resolved within hours and without data loss or infrastructure loss. This means you can switch back to the previously affected region without having to rebuild your data or infrastructure.
Local Disasters affecting a single AZ
A local disaster like fire or flooding may take a data center offline for a long time or even destroy it completely.
While a multi-AZ configuration is not strictly a disaster recovery solution, it is an important part of protecting against local disasters. Local disasters are more frequent than major disasters affecting an entire region, making protection against them even more valuable.
Let’s consider an extreme case where an entire availability zone is destroyed by a fire. A multi-AZ configuration will allow you to keep your application stack running in the other unaffected zones until you are ready to redeploy the affected resources to a new availability zone or do a graceful switch-over of the entire stack to another region — with no data loss.
Major Disasters affecting 2+ AZs or an entire Region
Because availability zones are geographically separate, a disaster that takes down two or more AZs simultaneously for an extended period of time must be of extremely high magnitude: a major earthquake, tsunami, or war. Thankfully, events like these are rare, and none have yet impacted AWS, Azure, or GCP. Nevertheless, a Disaster Recovery (DR) plan must be in place to account for eventualities affecting a whole region.
The length of downtime an organization can afford during a major regional disaster will dictate the DR plan: from restoring all data and infrastructure from scratch in a different region to keeping a full replica of the infrastructure and a “warm” copy of the data in a second region.

Latencies between AZs
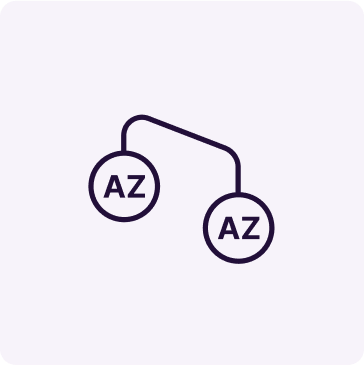
We have seen that the number one concern about a multi-AZ setup for database clusters (and Oracle RAC clusters specifically) is the extra latency between availability zones. Although it is true that latency between AZs is significantly higher compared to latencies within the same AZ, they are still low enough for synchronous replication or data mirroring. This includes very latency-sensitive operations, such as Cache Fusion in Oracle RAC database clusters.
Network latency between availability zones usually varies between 0.3 and 2 ms (milliseconds) depending on the region and specific pairs of AZs, but in most cases, it is less than 1 ms. This makes the multi-AZ deployments compliant with Oracle guidelines for extended-distance database clusters. You can also find and use the AZ pair with the least latency; for example, in the AWS us-west-2 region, usw2-az1 and usw2-az3 have a 0.3 ms latency between them. To learn how to identify inter-AZ latencies and set up the best configuration, read this article from FlashGrid’s knowledge base.
Latencies between regions
In most cases, latencies between regions are in the order of 10 to 100 ms (milliseconds) — prohibitively high for synchronous replication or mirroring of data. We cannot wait for a block of data to arrive in another region before “committing” a write; otherwise, writes would be too slow. Instead, asynchronous replication must be used between regions, which means the most recent data changes will not be in the secondary replica if the primary replica fails.
This makes the cross-region replication unsuitable protection against types of failures that are relatively frequent. Most cannot afford the cost of losing transactions so often.
However, when protecting against extremely rare major disasters that could abruptly take down an entire region, asynchronous DR replication has an acceptably small risk of losing the most recent transactions: it’s a reasonable tradeoff.
Achieving zero RPO (Recovery Point Objective)
Zero RPO means no data is lost in case an unexpected failure or a disaster hits. It is desirable and may be required in many cases, especially for transactional databases. The reason is simple – you don’t need to worry about how much and what type of data is lost. Dealing with even a small amount of data loss may lead to costly complications.
Achieving zero RPO is one of the foremost advantages of a multi-AZ configuration. A well-designed multi-AZ architecture protects against most infrastructure failure types and has a latency low enough for synchronous replication or data mirroring.
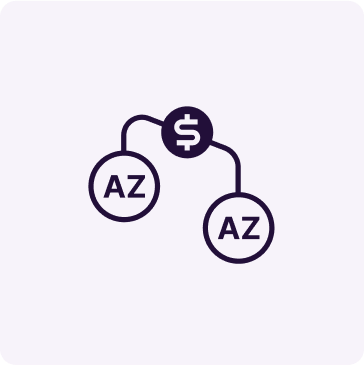
The cost of inter-AZ traffic
The cost of traffic within a single AZ is zero, but the traffic between AZs is not free. The price is typically USD 0.02 per GB (gigabyte). With large amounts of data transferred between AZs the cost of the traffic can become high. However, with a well-designed architecture and proper management of resources, the inter-AZ traffic costs can usually be minimized.
A good starting point is first to estimate the costs; here is an example: let’s assume a 100 TB database with 30% updates over 1 year plus 30% growth over 1 year. This means there are 60 TB of total data changes. Then, there is a multiplication factor, typically between 2 and 6, because of data-change duplication, such as write to the data file plus to the online (redo) log file. You can measure the precise multiplication factor in a test setup, but in this example, we will assume the multiplication factor is 3, which results in a total of 180 TB of data transferred between AZs over 1 year. Therefore, the yearly estimated price of traffic would be USD 3,600 (= 180,000 GB x 0.02 USD/GB). This cost may seem substantial, but it is orders of magnitude lower than the total costs of running a 100 TB database.
An important pitfall to avoid with inter-AZ traffic is the cost of continuously running write-intensive “test” workloads in a multi-AZ configuration because it would generate very large amounts of traffic. You can either limit the duration of such tests or use a single-AZ setup for the test environment.
Conclusion
Availability zones and multi-AZ configurations in the public clouds enable a new level of resiliency and fault-tolerance at a much lower cost than traditional self-managed “on-premises” data centers. The opportunity to leverage multi-AZ architectures for achieving better uptime SLA is a major reason to migrate to the cloud. Multi-AZ must be the default approach to high availability, fault tolerance, and local disaster protection when architecting mission-critical application stacks. Multi-region architectures and DR strategies can be layered on top of multi-AZ and will depend on specific business requirements and objectives.
To learn more about multi-AZ and multi-region configurations and discover how FlashGrid Cluster increases the uptime of Oracle databases, including Oracle RAC, on AWS, Azure, and GCP, contact us today.